Numpy -- Episode 3
Indexation, Découpage et Itération (indexing, slicing and iterating)
Dans les parties précédentes, vous avez vu comment créer un tableau et comment effectuer des opérations dessus. Dans cette partie, vous verrez comment manipuler ces objets. Vous apprendrez à sélectionner des éléments à travers des index et des tranches, afin d'obtenir les valeurs qu'ils contiennent ou de faire des affectations afin de changer leurs valeurs.
Indexation (Indexing)
Comme déjà vu au premier semestre l’indexation d’un tableau utilise toujours des crochets ([ ]) pour indexer les éléments d’un tableau de tel sorte que chaque élément peut être référencé individuellement pour diverses utilisations comme extraction d’une valeur, sélection d’un élément ou même assigner une nouvelle valeur. Lorsque vous créez un nouveau tableau, un index d'échelle approprié est également créé automatiquement (voir la figure)
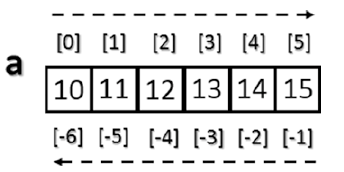
Afin d'accéder à un seul élément d'un tableau, vous pouvez vous référer à son index :
>>> a = np.arange(10, 16)
>>> a
array([10, 11, 12, 13, 14, 15])
>>> a[4]
14
>>> a[-1]
15
>>> a[-6]
10
Pour sélectionner plusieurs éléments à la fois, vous pouvez passer un tableau d'index entre crochets :
>>> a[[1, 3, 4]]
array([11, 13, 14])
Prenons maintenant le cas bidimensionnel, à savoir les matrices. Elles sont représentées sous forme de tableaux rectangulaires constitués de lignes et de colonnes, définies par deux axes, où l'axe 0 est représenté par les lignes et l'axe 1 est représenté par les colonnes. Ainsi l’indexation dans ce cas est représentée par deux paires de valeurs : la première valeur est l’index de la ligne et la deuxième valeur est l’index de la colonne. Par conséquent, si vous souhaitez accéder aux valeurs des éléments sélectionnés dans la matrice, vous utiliserez toujours des crochets, mais cette fois il y a deux valeurs [index des lignes, index des colonnes]
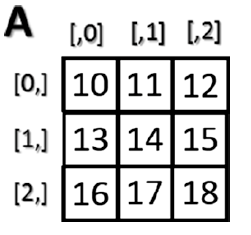
>>> A = np.arange(10, 19).reshape((3,3))
>>> A
array([[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
>>> A[1, 2]
15
Découpage (Slicing)
Le découpage vous permet d'extraire des parties d'un tableau pour générer de nouveaux tableaux. Selon la partie du tableau que vous souhaitez extraire (ou afficher), vous devez utiliser la syntaxe du slicing; c'est-à-dire que vous utiliserez une séquence de nombres séparés par des deux-points (:) entre crochets.
>>> a = np.arange(10, 16)
>>> a
array([10, 11, 12, 13, 14, 15])
>>> a[1:5]
array([11, 12, 13, 14])
>>> a[1:5:2]
array([11, 13])
On peut résumer le découpage par la syntaxe : tableau[début : fin : pas]
Si vous oubliez le premier nombre, NumPy va l’interpréter ce nombre comme 0 (c.à.d. l’élément initial du tableau). Si vous oublier le deuxième nombre, ceci va être interprété comme l’index maximal du tableau et si vous oublier le troisième nombre, ceci va être pris égale à 1.
>>> a[::2]
array([10, 12, 14])
>>> a[:5:2]
array([10, 12, 14])
>>> a[:5:]
array([10, 11, 12, 13, 14])
Dans le cas bidimensionnel, la syntaxe du slicing est la même que celle à 1 dimension mais il faut l’appliquer pour les lignes et les colonnes séparément. Par exemple, on veut extraire uniquement la première ligne :
>>> A = np.arange(10, 19).reshape((3,3))
>>> A[0, :]
array([10, 11, 12])
Même chose si on veut extraire la première colonne :
>>> A = np.arange(10, 19).reshape((3,3))
>>> A[: , 0]
array([10, 13, 16])
Itération (Iterating)
En Python, l'itération des éléments du tableau est vraiment très simple; il vous suffit d'utiliser le constructeur for :
>>> for i in a :
. . . print(i)
. . .
10
11
12
13
14
15
Même chose pour le cas à 2 dimensions :
>>> for ligne in A :
. . . print(ligne)
. . .
[10 11 12]
[13 14 15]
[16 17 18]
Si vous souhaitez effectuer l'itération élément par élément, vous pouvez utiliser la boucle for sur A.flat :
>>> for element in A.flat :
. . . print(element)
. . .
10
11
12
13
14
15
16
17
18
Cependant, malgré tout cela, NumPy propose une solution alternative et plus élégante que la boucle for. En règle générale, vous devez appliquer une fonction sur les lignes ou sur les colonnes ou sur un élément individuel. Si vous voulez créer une fonction d'agrégation qui renvoie une valeur calculée pour chaque colonne ou sur chaque ligne, il existe un moyen optimal qui laisse à NumPy la gestion de l'itération: la fonction apply_along_axis ().
Cette fonction prend trois arguments: la fonction d'agrégation, l'axe sur lequel appliquer l'itération et le tableau. Si l’option axis est égal à 0, l'itération évalue les éléments colonne par colonne, tandis que si l’option axis est égal à 1, l'itération évalue les éléments ligne par ligne. Par exemple, vous pouvez calculer les valeurs moyennes d'abord par colonne puis par ligne:
>>> np.apply_along_axis(np.mean, axis = 0, arr = A)
array([13., 14., 15.])
>>> np.apply_along_axis(np.mean, axis = 1, arr = A)
array([11., 14., 17.])